Abstract
Zero-shot text-to-speech (TTS) must generate speech from text while preserving the speaker characteristics of a short reference utterance. Recent non-autoregressive systems improve decoding efficiency, but they often bridge the text--speech length mismatch with duration predictors, filler-token padding, or text upsampling, and inject reference speech through sequence-level conditioning. We propose M3-TTS, a multi-modal, multi-stream, and modulation-based diffusion Transformer for reference-conditioned masked acoustic generation. Its core design is a native two-stream architecture, termed Self-Adaptive Joint Representation (SAJR), where text tokens and speech representations keep their original lengths and interact through packed joint self-attention. M3-TTS further uses a joint-to-audio generation pipeline to separate cross-modal correspondence learning from acoustic refinement, together with AdaLN-style acoustic prompting to inject speaker information in a unified acoustic representation space. Experiments show that the FBank-based M3-TTS reaches 1.52% WER on English and 1.35% CER on Chinese in the 24kHz Seed-TTS comparison, while the Mel-VAE variant reduces RTF to 0.12.
Model Architecture
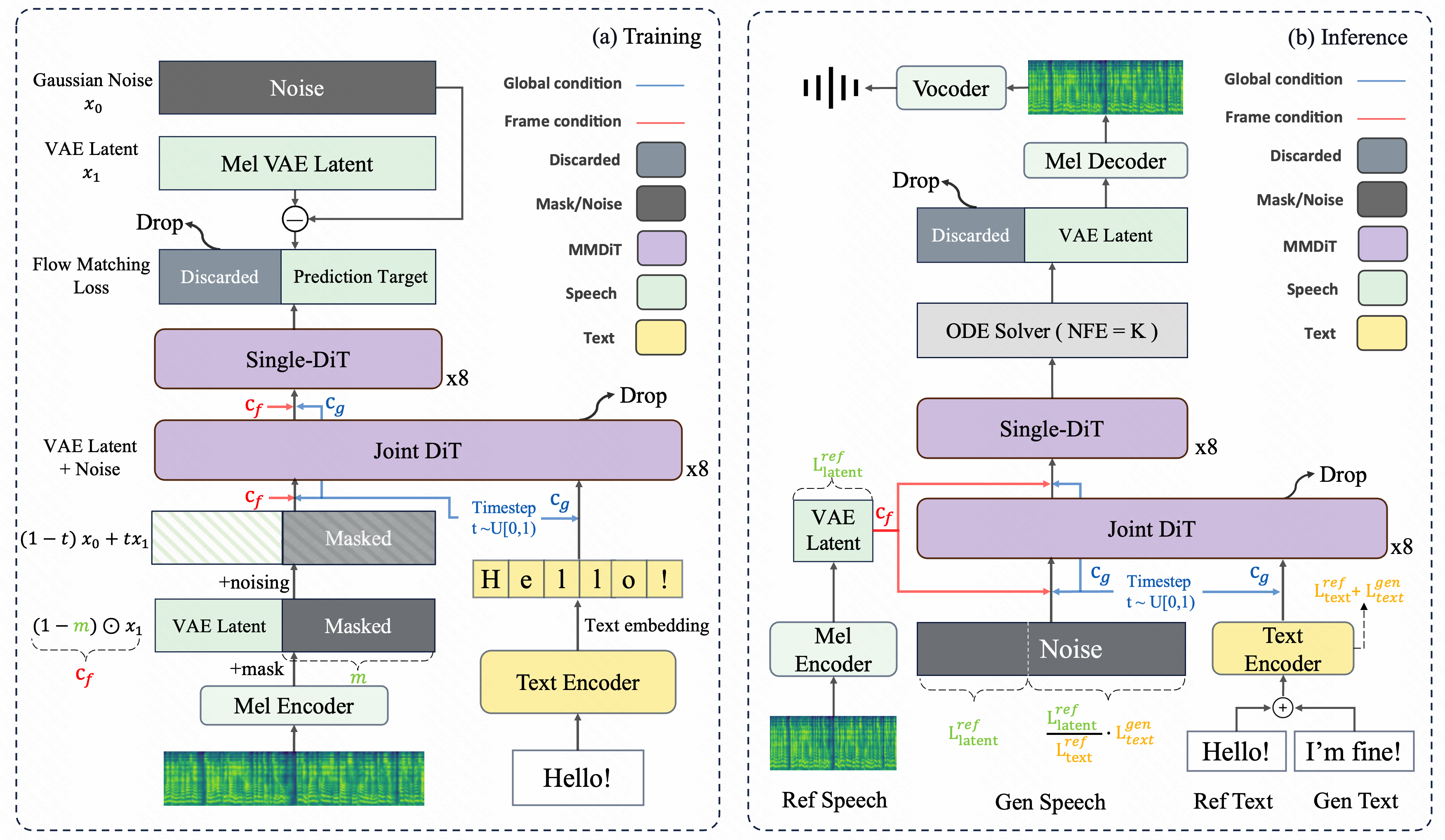
Zero Shot TTS Task
| Text | gt | F5-TTS | ZipVoice | M3-TTS(VAE) | M3-TTS(Fbank) |
|---|---|---|---|---|---|
| It seemed the ordained order of things that dogs should work. | |||||
| Construction requires study and observation. | |||||
| She was one of several driven onto the beach. | |||||
| Why Born Enslaved! | |||||
| 因为我们悄悄走过,所以当时那些惊涛骇浪都烟消云散。 | |||||
| 来到河边,蹦豆打开渔网一看,好失望呀。 | |||||
| 自动驾驶将大幅提升出行安全,效率。 | |||||
| 我们将为全球市场的可持续发展贡献力量。 |